Instructions
Objective
Write a program to format the output of paragraphs in Haskell.
Requirements and Specifications
In this problem, you will write a function for laying out monospaced paragraphs within a fixed margin width. We will represent paragraphs as lists of words:
["I","will","begin","the","story","of","my","adventures",
"with","a","certain","morning","early","in","the","month",
"of","June,","the","year","of","grace","1751,","when","I",
"took","the","key","for","the","last","time","out","of",
"the","door","of","my","father's","house."]
This is the first sentence of "Kidnapped" by Robert Louis Stevenson:
(https://en.wikisource.org/wiki/Kidnapped_(Stevenson)/Chapter_1)
The plan is to turn a list of words into a list of lines by adding words to a line with single spaces between them until adding one would go over the intended width. As a special case, we always put at least one word on each line, even if that would mean going over the limit. For example, if the width is 40, then we would get the following layout:
[["I","will","begin","the","story","of","my","adventures"],
["with","a","certain","morning","early","in","the"],
["month","of","June,","the","year","of","grace","1751,"],
... ]
In this example, the first line is length 39 after putting in the spaces. Adding 'with' would take us over the limit, so we start a new line.
We will make the following simplifying assumptions:
Each word takes up the same amount of space as it has,
characters (this is not true for all of the Unicode character set, and only really works for ASCII if we assume a monospaced font).
Each space character ' ' takes up exactly one space.
We encode these assumptions into the following function, which you will use to keep track of the current column words are being placed in. Given a current column 'col' and a word 'word', 'plusCol col word' returns the column we'll be in if we add a space and 'word' to the line: -}
Screenshots of output
Source Code
{-# OPTIONS_GHC -fwarn-incomplete-patterns #-}
module Ex1 where
import Prelude hiding (words)
import qualified Prelude as P
{----------------------------------------------------------------------}
{- CS316 (2020/21) EXERCISE 1 : FIRST-ORDER PROGRAMMING -}
{----------------------------------------------------------------------}
{- Please read this file carefully. Questions are numbered 1.X.Y and
usually consist of unfinished definitions that you will have to
fill in. The marks available for each question are listed
underneath the question and answer space. There are four
independent parts, with 30 questions overall. -}
{----------------------------------------------------------------------}
{- PART 1 : FUN(ctional) WITH LISTS -}
{----------------------------------------------------------------------}
{- 1.1.0 Concatenation of lists.
The standard library infix operator ++ concatenates (appends) two
lists. Use it to write a function in pattern matching style which
concatenates a list of lists. We have given you an unfinished
definition which you should refine into suitable cases and
complete. -}
concatLists :: [[x]] -> [x]
concatLists [] = []
concatLists [x] = x
concatLists (x:xs) = concatLists ((x ++ head(xs)) : tail(xs))
{- It may help to think concretely:
(a) What should
concatLists [[1], [2,3], [4,5,6]]
be? [1,2,3,4,5,6]
(b) What should
concatLists [[2,3], [4,5,6]]
be? [2,3,4,5,6]
(c) How do you combine the list '[1]' with the answer to (b) to
make the answer to (a)? Remember that '[[1], [2,3], [4,5,6]]' is
syntactic sugar for '[1]:[2,3]:[4,5,6]:[]'. -}
{- 2 MARKS -}
{- 1.1.1 Cons-ing an element to every list in a list of lists.
The cons constructor ':' takes an element 'x' and a list 'xs', and
creates a new list 'x:xs' with 'x' at the head and 'xs' at the
tail. (See the Week 01 videos and notes.)
Write a function that performs the cons operation to every list in
a list of lists. For example:
consAll 1 [[2,3],[4,5]] == [[1,2,3],[1,4,5]]
consAll 1 [[]] == [[1]]
consAll 1 [] == []
-}
consAll :: a -> [[a]] -> [[a]]
consAll _ [] = []
consAll x (y:ys) = (x:y) : (consAll x ys)
{- 2 MARKS -}
{- 1.1.2 Splitting Lists.
The function 'splitOn' splits a list at every occurence of some
value. Examples:
splitOn 0 [1,2,0,3,0] == [[1,2],[3],[]]
splitOn 0 [1,2,0,3,0,4] == [[1,2],[3],[4]]
splitOn 0 [] == [[]]
splitOn 0 [0] == [[],[]]
splitOn 0 [0,0] == [[],[],[]]
Because strings are lists of 'Char's, 'splitOn' is a useful way of
breaking down strings:
splitOn ':' "Ty Per:ty.per@example.com" == ["Ty Per", "ty.per@example.com"]
Write the function 'splitOnHelper' that 'splitOn' uses to work. -}
splitOn :: Eq a => a -> [a] -> [[a]]
splitOn splitChar xs = splitOnHelper splitChar [] xs
splitOnHelper :: Eq a => a -> [a] -> [a] -> [[a]]
splitOnHelper s x [] = [reverse x]
splitOnHelper s group (x:xs) = if s == x then
(reverse group) : splitOnHelper s [] xs
else
splitOnHelper s (x:group) xs
{- HINT: 'splitOnHelper' works by gathering elements of the input list
'xs' in 'groups' until it sees an occurence of the splitting
value. When it sees a splitting value, it returns a new list
element containing the current group (reversed back to normal), and
then carries on with a new empty group. When it runs out of
elements to process, the current group is reversed and becomes the
last element of the output list.
You can use the standard library function 'reverse' to reverse
lists.
The arguments to 'splitOnHelper' are:
splitOnHelper s group xs
- 's :: a' the value to split on
- 'group :: [a]' the list of values in the current group, in reverse order
- 'xs :: [a]' the input list of elements remaining to be processed. -}
{- 3 MARKS -}
{- 1.1.3 Removing Empties.
The function 'splitOn' generates empty lists when there are
consecutive occurrences of the splitting value. In some cases, we
don't care about the empty lists. Write a function that takes a
list of lists, and returns a list only containing the non-empty
elements in the same order. Examples:
removeEmpty [[1],[],[2]] == [[1],[2]]
removeEmpty [[],[]] == []
removeEmpty ["hello","","world"] == ["hello","world"] -}
removeEmpty :: [[a]] -> [[a]]
removeEmpty [] = []
removeEmpty ([]:xs) = removeEmpty xs
removeEmpty (x:xs) = x : removeEmpty xs
{- 1 MARK -}
{- 1.1.4 Splitting into words.
Using 'splitOn' and 'removeEmpty', write a function that splits a
string into words. Assume that words are separated by spaces ' '
and that words are not empty. Examples:
words "hello world" == ["hello","world"]
words "hello world" == ["hello", "world"]
words "" == []
words " " == []
words "hello, world" == ["hello,", "world"] -}
words :: String -> [String]
words xs = removeEmpty ( splitOn ' ' xs)
{- 1 MARK -}
{- 1.1.5 Formatting paragraphs.
In this problem, you will write a function for laying out
monospaced paragraphs within a fixed margin width. We will
represent paragraphs as lists of words:
["I","will","begin","the","story","of","my","adventures",
"with","a","certain","morning","early","in","the","month",
"of","June,","the","year","of","grace","1751,","when","I",
"took","the","key","for","the","last","time","out","of",
"the","door","of","my","father's","house."]
(This is the first sentence of "Kidnapped" by Robert Louis Stevenson:
https://en.wikisource.org/wiki/Kidnapped_(Stevenson)/Chapter_1 )
The plan is to turn a list of words into a list of lines by adding
words to a line with single spaces between them until adding one
would go over the intended width. As a special case, we always put
at least one word on each line, even if that would mean going over
the limit. For example, if the width is 40, then we would get the
following layout:
[["I","will","begin","the","story","of","my","adventures"],
["with","a","certain","morning","early","in","the"],
["month","of","June,","the","year","of","grace","1751,"],
... ]
In this example, the first line is length 39 after putting in the
spaces. Adding 'with' would take us over the limit, so we start a
new line.
We will make the following simplifying assumptions:
1. Each word takes up the same amount of space as it has
characters (this is not true for all of the Unicode character
set, and only really works for ASCII if we assume a monospaced
font).
2. Each space character ' ' takes up exactly one space.
We encode these assumptions into the following function, which you
will use to keep track of the current column words are being placed
in. Given a current column 'col' and a word 'word', 'plusCol col
word' returns the column we'll be in if we add a space and 'word'
to the line: -}
plusWord :: Int -> String -> Int
plusWord col word = col + 1 + length word
{- Now you write the following function 'layOutLines'. The arguments are
as follows:
layOutLines w col line words
- 'w :: Int' is the target width, use this to determine whether to start
a new line or not.
- 'col :: Int' is the current column we are in, it represents how
wide 'line' is once spaces are added.
- 'line :: [String]' is the list of words in the current line, in
reverse order.
- 'words :: [String]' is the list of words remaining to be added
to some lines.
The whole function ought to return the list of lines generated. See
below for hints. -}
layOutLines :: Int -> Int -> [String] -> [String] -> [[String]]
layOutLines w col [] [] = []
layOutLines w col line [] = [reverse line]
layOutLines w 0 line (x:xs) = layOutLines w (length x) (x:line) xs
layOutLines w col line (x:xs) = if (plusWord col x) <= w then
layOutLines w (plusWord col x) (x : line) xs
else
(reverse line) : layOutLines w 0 [] (x:xs)
{- 5 MARKS -}
{- HINT: There are four cases of interest:
1. We have no words remaining (words is []), and the line is empty.
2. We have no words remaining, but there is something on this line.
3. There are some words, but we are at the start of the line.
4. There are some words, and we are in the middle of a line:
4(a) the word fits on the line
4(b) the word doesn't fit on the line
Case three is important, because otherwise we never lay out a word
that is longer than a line!
HINT: the structure of the function is very similar to 'splitOn'
above, except that the condition used to decide when to split into
groups is slightly different. -}
{- Once you have written 'layOutParagraph', the following functions will
start working, which call 'layOutParagraph' with the right initial
values.
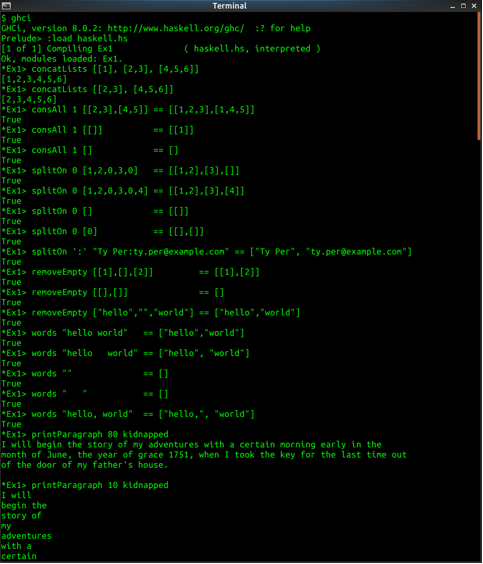
'formatParagraph 80 kidnapped' should return:
[["I","will","begin","the","story","of","my","adventures","with","a","certain","morning","early","in","the"],
["month","of","June,","the","year","of","grace","1751,","when","I","took","the","key","for","the","last","time","out"],
["of","the","door","of","my","father's","house."]]
Some examples of 'printParagraph':
*Ex1> printParagraph 80 kidnapped
I will begin the story of my adventures with a certain morning early in the
month of June, the year of grace 1751, when I took the key for the last time out
of the door of my father's house.
*Ex1> printParagraph 10 kidnapped
I will
begin the
story of
my
adventures
with a
certain
morning
early in
the month
of June,
the year
of grace
751, when
I took the
key for
the last
time out
of the
door of my
father's
house.
-}
formatParagraph :: Int -> [String] -> [[String]]
formatParagraph w = layOutLines w 0 []
printParagraph :: Int -> [String] -> IO ()
printParagraph w = putStrLn . unlines . map unwords . formatParagraph w
{- The following are two pieces of text that you can use for testing. -}
-- https://en.wikisource.org/wiki/Kidnapped_(Stevenson)/Chapter_1
kidnapped :: [String]
kidnapped = P.words "I will begin the story of my adventures with a certain morning early in the month of June, the year of grace 1751, when I took the key for the last time out of the door of my father's house."
-- https://en.wikisource.org/wiki/Frankenstein,_or_the_Modern_Prometheus_(Revised_Edition,_1831)/Preface
frankenstein :: [String]
frankenstein = P.words "The event on which this fiction is founded, has been supposed, by Dr. Darwin, and some of the physiological writers of Germany, as not of impossible occurrence. I shall not be supposed as according the remotest degree of serious faith to such an imagination ; yet, in assuming it as the basis of a work of fancy, I have not considered myself as merely weaving a series of supernatural terrors. The event on which the interest of the story depends is exempt from the disadvantages of a mere tale of spectres or enchantment. It was recommended by the novelty of the situations which it developes ; and, however impossible as a physical fact, affords a point of view to the imagination for the delineating of human passions more comprehensive and commanding than any which the ordinary relations of existing events can yield."
{----------------------------------------------------------------------}
{- PART 2 : CURSORS -}
{----------------------------------------------------------------------}
{- In this part of the exercise, you will implement a simple line
editor.
The following datatype represents a 'pointer' into, or 'cursor' in,
a list of characters. It allows us to edit the middle of the list
without having to search all the way down from the head each
time. In this section, we will build up to having a rudimentary
line based text editor. -}
data Cursor
= Within [Char] Char [Char]
| AtEnd [Char]
deriving Show
{- The 'Cursor' datatype has two constructors:
'Within before point after'
-- represents a cursor in the middle of the list
- 'before' is the content of the list before the cursor, in reverse order
- 'point' is the item under the cursor
- 'after' is the content of the list after the cursor, in normal order
'AtEnd before'
-- represents a cursor just after the end of a list
- 'before' is the content of the list before the cursor
Examples (the '^' represents where the cursor is):
Within "ba" 'c' "de" represents abcde
^
Within "a" 'b' "cde" represents abcde
^
Within "" 'a' "bcde" represents abcde
^
AtEnd "edcba" represents abcde
^
The function 'displayCursor' gives an ASCII art rendering of a
cursor. Try it out in GHCi to see how it represents different
cursor positions, and to get yourself familiar with the cursor
representation. For example, try:
*Ex1> displayCursor (Within "ba" 'c' "de")
and the other example cursors above. -}
revAppend :: [a] -> [a] -> [a]
revAppend [] ys = ys
revAppend (x:xs) ys = revAppend xs (x:ys)
displayCursor :: Cursor -> String
displayCursor (AtEnd before) = revAppend before "[_]"
displayCursor (Within before point after) = revAppend before ('[':point:']':after)
{- 'toCursor' converts a list into a cursor, placing the cursor at the
start of the list. Try it out in GHCi, along with the displayCursor
function. -}
toCursor :: String -> Cursor
toCursor [] = AtEnd []
toCursor (x:xs) = Within [] x xs
{- 'fromCursor' forgets the position of the cursor in a list and returns
the list. Again, try this function out in GHCi to familiarise
yourself with the cursor representation. Try lots of different
examples. -}
fromCursor :: Cursor -> String
fromCursor (AtEnd before) = revAppend before []
fromCursor (Within before point after) = revAppend before (point:after)
{- 'getPoint' reads the item currently under the cursor. If the cursor
is at the end of the line, it returns 'Nothing'. Otherwise, it
returns 'Just point'. -}
getPoint :: Cursor -> Maybe Char
getPoint (AtEnd _) = Nothing
getPoint (Within _ point _) = Just point
{- 1.2.0 Querying a cursor. Write two functions that (a) test whether or
not a cursor is at the end of the line; and (b) test whether or not
a cursor is at the start of the line. -}
atEnd :: Cursor -> Bool
atEnd (AtEnd _) = True
atEnd (Within _ _ _) = False
atStart :: Cursor -> Bool
atStart (AtEnd _) = False
atStart (Within [] _ _) = True
atStart (Within _ _ _) = False
{- 1 MARK -}
{- 1.2.1 Movement.
Here is a function that moves the cursor one step to the
right. There are three cases:
1. If we are already at the end ('AtEnd'), we do nothing and
return the cursor as is.
2. If we are one before the end (the 'after' list is empty), the
cursor becomes 'AtEnd', moving the point into the head of the
'before' list.
3. If the cursor is in the middle, we move the current point into
the 'before' list, and take the head of the 'after' list as
the new point.
This definition illustrates why I chose to represent the 'before'
list in reverse: it makes moving the cursor into a quick operation
of prepending elements on to lists. -}
moveRight :: Cursor -> Cursor
moveRight (AtEnd before) = AtEnd before
moveRight (Within before point []) = AtEnd (point:before)
moveRight (Within before point (a:after)) = Within (point:before) a after
{- Have a play with this function in GHCi to experiment with how it
works.
Now you write the 'moveLeft' function. There will be four cases:
1. The cursor is at the end and start of an empty line
2. The cursor is at the end of a non-empty line
3. The cursor is at the start of a non-empty line
4. The cursor is within a non-empty line.
Turn these cases into Haskell patterns and work out what to do in
each case.
Some examples:
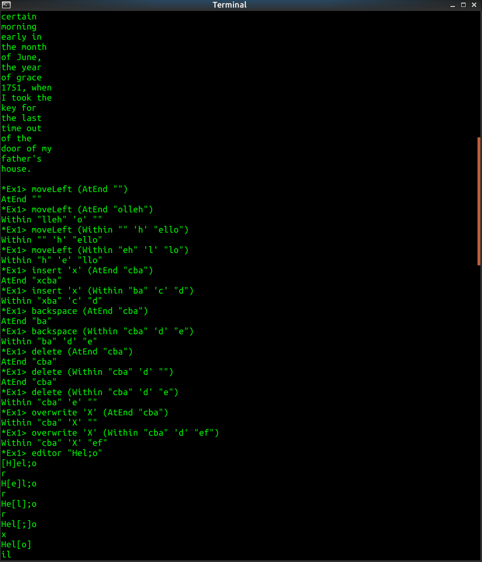
moveLeft (AtEnd "") == AtEnd ""
moveLeft (AtEnd "olleh") == Within "lleh" 'o' ""
moveLeft (Within "" 'h' "ello") == Within "" 'h' "ello"
moveLeft (Within "eh" 'l' "lo") == Within "h" 'e' "llo"
A helpful thing to remember is that moveLeft (like moveRight)
should not alter the content of the cursor in any way. More
formally, for all cursors 'c', 'fromCursor c == fromCursor
(moveLeft c)'. -}
moveLeft :: Cursor -> Cursor
moveLeft (AtEnd []) = AtEnd []
moveLeft (AtEnd (x:xs)) = Within xs x []
moveLeft (Within [] x xs) = (Within [] x xs)
moveLeft (Within (x:xs) y ys) = (Within xs x (y:ys))
{- 1 MARK -}
{- 1.2.2 Inserting Text.
'moveRight' and 'moveLeft' do not alter the content of the
cursor. Now you will write a function that does edit the
text. 'insert x cur' should insert the value 'x' "before" the
cursor (in a similar way to pressing a key inserts a character
"before" the cursor in your text editor). Examples:
insert 'x' (AtEnd "cba") == AtEnd "xcba"
insert 'x' (Within "ba" 'c' "d") == Within "xba" 'c' "d"
-}
insert :: Char -> Cursor -> Cursor
insert x (AtEnd xs) = AtEnd (x:xs)
insert x (Within xs y ys) = Within (x:xs) y ys
{- 1 MARK -}
{- 1.2.3 Backspace.
Write a function that edits the cursor in the same way as your
backspace key does. That is, it removes the character to the left
of the cursor. Remember to think carefully about the possible edge
cases. You may want to experiment with the backspace key in your
text editor. Be careful not to delete the rest of your answers!
backspace (AtEnd "cba") == AtEnd "ba"
backspace (Within "cba" 'd' "e") == Within "ba" 'd' "e"
-}
backspace :: Cursor -> Cursor
backspace (AtEnd []) = AtEnd []
backspace (AtEnd (x:xs)) = AtEnd xs
backspace (Within [] x xs) = Within [] x xs
backspace (Within (x:xs) y ys) = Within xs y ys
{- 1 MARK -}
{- 1.2.4 Deletion.
Write a function that deletes the element under the cursor (similar
to pressing the 'delete' key in a text editor (not the backspace
key!)). If there is no element under the cursor, then nothing
happens. If there is any element to the right of the cursor, it is
used to fill in the gap left. Examples:
delete (AtEnd "cba") == AtEnd "cba"
delete (Within "cba" 'd' "") == AtEnd "cba"
delete (Within "cba" 'd' "e") == Within "cba" 'e' ""
-}
delete :: Cursor -> Cursor
delete (AtEnd xs) = AtEnd xs
delete (Within xs x []) = AtEnd xs
delete (Within xs x (y:ys)) = Within xs y ys
{- 1 MARK -}
{- 1.2.5 Overwrite
Write another editing function that /replaces/ the element
underneath the cursor with the given one, and does not move the
cursor. If the cursor is at the end of the line, it should act as
if the new character replaces the 'virtual' character at the end of
the line. The cursor remains on the position of the overwritten
character.
overwrite 'X' (AtEnd "cba") = Within "cba" 'X' ""
overwrite 'X' (Within "cba" 'd' "ef") = Within "cba" 'X' "ef"
-}
overwrite :: Char -> Cursor -> Cursor
overwrite x (AtEnd xs) = Within xs x []
overwrite x (Within xs y ys) = Within xs x ys
{- 1 MARK -}
{- 1.2.6 Multiple lines.
The Cursor datatype represents a single line. We will now upgrade
this to a multiline editor. The structure for implementing a
multiline editor is very similar to the structure used for
implementing the cursor.
Here is the 'LineCursor' type: -}
data LineCursor
= LineCursor [String] Cursor [String]
deriving Show
{- A 'LineCursor' value has three parts:
LineCursor above line below
It consists of a list 'above' holding the lines above the cursor
(in reverse), the cursor on the current line ('line'), and a list
containing the lines below the current cursor. Notice the
similarity to the 'Within' constructor in the 'Cursor'
datatype. There is no analogue of the 'AtEnd' constructor because
it is not possible to be off the end of the file.
Implement the following functions.
'currentLine' returns the 'Cursor' on the current line.
'updateLine' replaces the 'line' cursor with a new one.
'moveUp' simulates going up a line:
- if the current line is the first one ('before' is empty), then
the same LineCursor is returned.
- otherwise, the current line is converted to a String (using
'fromCursor' from the Ex1.hs file) and put into 'below', and
the line above is converted to a cursor (using 'toCursor') and
used as the new current line.
'moveDown' is similar to 'moveUp' but simulates moving down a line. -}
currentLine :: LineCursor -> Cursor
currentLine (LineCursor xs x ys)= x
updateLine :: LineCursor -> Cursor -> LineCursor
updateLine (LineCursor xs x ys) y = LineCursor xs y ys
moveUp :: LineCursor -> LineCursor
moveUp (LineCursor [] x xs) = LineCursor [] x xs
moveUp (LineCursor (x:xs) y ys) = LineCursor xs (toCursor x) ((fromCursor y):ys)
moveDown :: LineCursor -> LineCursor
moveDown (LineCursor xs y []) = LineCursor xs y []
moveDown (LineCursor xs x (y:ys)) = LineCursor ((fromCursor x):xs) (toCursor y) ys
{- 6 MARKS -}
{- Once you have some or all of the functions above written, you will be
able to use them as a simple text editor. Running
λ> editor "Hello"
[H]ello
starts the editor and displays a cursor. Commands are entered by
typing them and pressing 'Enter'. The commands are:
'q' -- quits
'r' -- move right
'l' -- move left (needs the moveLeft function written)
'iX' -- inserts 'X' (needs the 'insert' function)
'oX' -- overwrites the current character with 'X' (needs 'overwrite')
'b' -- removes the character directly to the left of the cursor (needs 'backspace')
'x' -- removes the charater underneath the cursor (needs 'delete')
An example:
λ> editor "Hel;o"
[H]el;o
r
H[e]l;o
r
He[l];o
r
Hel[;]o
x
Hel[o]
il
Hell[o]
q
"Hello"
-}
data Result a
= Continue a
| Stop
| Error
deriving Show
decode :: String -> Cursor -> Result Cursor
decode "q" cursor = Stop
decode "l" cursor = Continue (moveLeft cursor)
decode "r" cursor = Continue (moveRight cursor)
decode ['i',c] cursor = Continue (insert c cursor)
decode ['o',c] cursor = Continue (overwrite c cursor)
decode "b" cursor = Continue (backspace cursor)
decode "x" cursor = Continue (delete cursor)
decode _ cursor = Error
editor :: String -> IO String
editor string = displayLoop initialState
where
initialState = toCursor string
displayLoop cursor = do
putStrLn (displayCursor cursor)
cmd <- getLine
case decode cmd cursor of
Stop -> do putStrLn ""; return (fromCursor cursor)
Continue cursor -> displayLoop cursor
Error -> do putStrLn "???"; displayLoop cursor
{----------------------------------------------------------------------}
{- PART 3 : CONFIGURATIONS -}
{----------------------------------------------------------------------}
{- This part of the exercise asks you to write some functions for
manipulating simple key/value stores, such as might be used to
store configuration information for a service.
The first three functions
cover "flat" key/value stores, where keys are atomic and each key
is associated to at most one value. The remaining questions in this
section deal with "nested" or "heirarchical" key/value stores,
where we have key value stores nested within one another (like
folders in a file system). -}
{- 1.3.0 lookupKey
We represent flat key/value stores as lists of pairs of keys and
values, where all the keys are in sorted order and duplicate keys
are not allowed. For instance, the list
[("a",1), ("b",2)]
represents a store where the key "a" has value 1, and the key "b"
has value 2.
(See the Week 02 videos and notes for examples of how to deal with
sorted lists.)
Write a function that looks up a key in a key/value store
represented in this way. If the key is not there it should return
'Nothing'.
Examples:
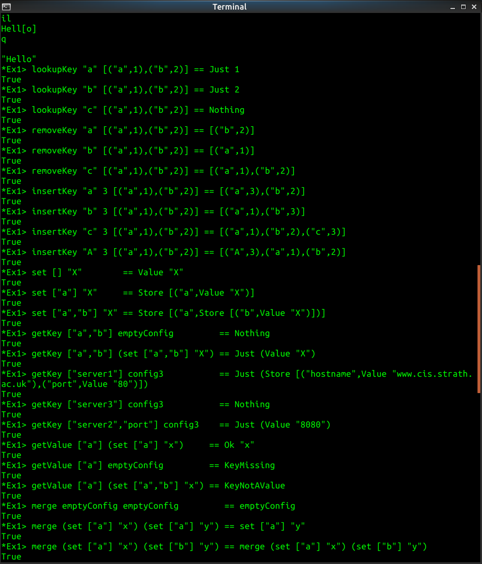
lookupKey "a" [("a",1),("b",2)] == Just 1
lookupKey "b" [("a",1),("b",2)] == Just 2
lookupKey "c" [("a",1),("b",2)] == Nothing
-}
lookupKey :: Ord k => k -> [(k,v)] -> Maybe v
lookupKey s [] = Nothing
lookupKey s ((k,v):xs)
| s < k = Nothing
| s == k = Just v
| otherwise = lookupKey s xs
{- 1 MARK -}
{- 1.3.1 removeKey
Write a function that removes a key from a key/value store. That
is, it takes a key and key/value store as input, and returns a
key/value store with that key missing. If the key is not there,
then it ought to return the key/value store unchanged.
Examples:
removeKey "a" [("a",1),("b",2)] == [("b",2)]
removeKey "b" [("a",1),("b",2)] == [("a",1)]
removeKey "c" [("a",1),("b",2)] == [("a",1),("b",2)]
-}
removeKey :: Ord k => k -> [(k,v)] -> [(k,v)]
removeKey s [] = []
removeKey s ((k,v):xs)
| s < k = ((k,v):xs)
| s == k = xs
| otherwise = (k,v) : (removeKey s xs)
{- 1 MARK -}
{- 1.3.2 insertKey
Write a function that inserts a key/value pair into a key/value
store. If the key is already present, then it should overwrite that
key's value. If the key does not exist then it should add that
key. Be sure to maintain the ordering of keys.
insertKey "a" 3 [("a",1),("b",2)] == [("a",3),("b",2)]
insertKey "b" 3 [("a",1),("b",2)] == [("a",1),("b",3)]
insertKey "c" 3 [("a",1),("b",2)] == [("a",1),("b",2),("c",3)]
insertKey "A" 3 [("a",1),("b",2)] == [("A",3),("a",1),("b",2)]
-}
insertKey :: Ord k => k -> v -> [(k,v)] -> [(k,v)]
insertKey k v [] = [(k,v)]
insertKey k v ((k',v'):xs)
| k < k' = ((k,v):(k',v'):xs)
| k == k' = ((k,v):xs)
| otherwise = (k',v') : (insertKey k v xs)
{- 2 MARKS -}
{- We now look at hierarchical key/value stores. Instead of being a flat
list of keys with associated values, we will allow keys to be
associated with nested key/value stores as well as values. This
will act similarly to how folders are nested on a file system.
We represent nested key/value stores using the following datatype: -}
data Config
= Value String
| Store [(String, Config)]
deriving (Show, Eq)
{- The constructor 'Value' represents a single value. So the 'Config'
'Value "www.cis.strath.ac.uk"' is a configuration containing the
single value "www.cis.strath.ac.uk".
The constructor 'Store' represents a store containing a list of
'String' keys with associated configurations. The pairs are
expected to be in sorted order, with no duplicate keys (as
above). For example, the 'Config's: -}
config1 :: Config
config1 = Store [("hostname",Value "www.cis.strath.ac.uk"),("port",Value "80")]
config2 :: Config
config2 = Store [("hostname",Value "www.strath.ac.uk"),("port",Value "8080")]
{- Represent two different stores with the same keys. The first
associates "www.cis.strath.ac.uk" to "hostname", and "80" to
"port". The second associates "www.cis.strath.ac.uk" and "8080".
We can combine these into a single 'Config': -}
config3 :: Config
config3 = Store [("server1", config1),("server2", config2)]
{- If you evaluate 'config3' in GHCi, it will show you the full 'Config'
value.
Keys into a store are now lists of 'String's, so we make a type
synonym to make our function types easier to read: -}
type Key = [String]
{- 1.3.3 emptyConfig
Fill in the definition of 'emptyConfig' with a 'Config' that has no
keys and no values. The wrong answer is 'Value ""', which has a
single value. -}
emptyConfig :: Config
emptyConfig = Store []
{- 1 MARK -}
{- 1.3.4 set
Fill in the definition of 'set'. This function should take a 'Key'
and a 'String' and return the 'Config' that associates that key
with that value.
Examples:
set [] "X" == Value "X"
set ["a"] "X" == Store [("a",Value "X")]
set ["a","b"] "X" == Store [("a",Store [("b",Value "X")])]
-}
set :: Key -> String -> Config
set [] xs = Value xs
set (x:xs) ys = Store [(x, (set xs ys))]
{- 1 MARK -}
{- 1.3.5 getKey
The function 'getKey' should return the nested configuration
associated with the given 'Key'.
Examples:
getKey ["a","b"] emptyConfig == Nothing
getKey ["a","b"] (set ["a","b"] "X") == Just (Value "X")
getKey ["server1"] config3 == Just (Store [("hostname",Value "www.cis.strath.ac.uk"),("port",Value "80")])
getKey ["server3"] config3 == Nothing
getKey ["server2","port"] config3 == Just (Value "8080")
You will find it useful to use the 'lookupKey' function defined
above. You will have to use a 'case' expression. -}
getKey :: Key -> Config -> Maybe Config
getKey [] c = Just c
getKey _ (Store []) = Nothing
getKey _ (Value _) = Nothing
getKey (x:xs) (Store cs) = case lookup x cs of
Nothing -> Nothing
Just v -> getKey xs v
{- 2 MARKS -}
{- 1.3.6 getValue
The 'getKey' function returns the 'Config' associated with a key,
but sometimes we'd like to just get any value associated with a key
and raise an error when we get anything else.
This datatype represents the possible outcomes of trying to find a
key in a configuration: -}
data ValueResult
= Ok String
| KeyMissing
| KeyNotAValue
deriving (Show, Eq)
{- Implement 'getValue', which uses 'getKey' and returns 'Ok s' if the
key is associated with 'Value s', 'KeyMissing' if the key is not
found, and 'KeyNotAString' if the key is there, but isn't a value.
Examples:
getValue ["a"] (set ["a"] "x") == Ok "x"
getValue ["a"] emptyConfig == KeyMissing
getValue ["a"] (set ["a","b"] "x") == KeyNotAValue
-}
getValue :: Key -> Config -> ValueResult
getValue k c = case getKey k c of
Nothing -> KeyMissing
Just (Value x) -> Ok x
Just (Store _) -> KeyNotAValue
{- 2 MARKS -}
{- 1.3.7 Merging configurations.
Write a function that merges two configurations together into a
single configuration. The rules are:
- Every key in the output must exist in one of the two input
configurations.
- If a key appears in only one configuration, it has the same value
in the output as it did in that configuration.
- If a key appears in both configurations, we take the value from
the *second* input configuration.
Here are some examples:
merge emptyConfig emptyConfig == emptyConfig
merge (set ["a"] "x") (set ["a"] "y") == set ["a"] "y"
merge (set ["a"] "x") (set ["b"] "y") == merge (set ["a"] "x") (set ["b"] "y")
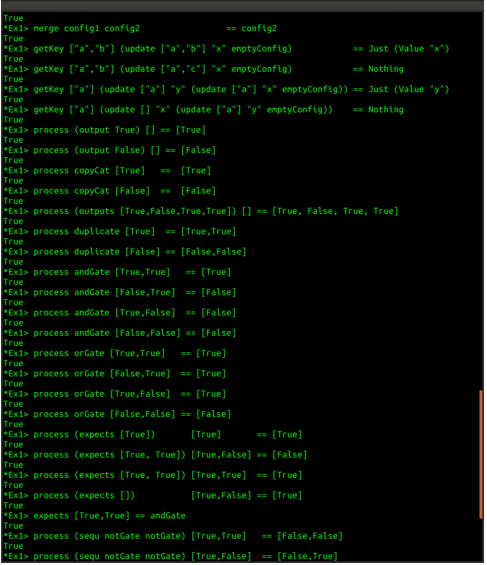
merge config1 config2 == config2
You will have to write *two* functions that call each
other. 'merge' merges two 'Config's together, so it needs to check
for all combinations of 'Value' and 'Store' and do the right
thing. When merging two 'Store's, it will need to call on
'mergeKVs' which should merge two key/value stores, making sure to
keep everything in order (see the mergesort example from Week
02). When merging two identical keys, 'mergeKVs' will call 'merge'. -}
merge :: Config -> Config -> Config
merge (Value v) (Value v') = Value v'
merge (Value v) (Store s) = Store s
merge (Store s) (Value v) = Value v
merge (Store []) (Store s) = Store s
merge (Store s) (Store []) = Store s
merge (Store s) (Store s') = Store (mergeKVs s s')
mergeKVs :: [(String,Config)] -> [(String,Config)] -> [(String,Config)]
mergeKVs xs [] = xs
mergeKVs [] xs = xs
mergeKVs ((k,v):xs) ((k',v'):ys)
| k < k' = (k, v) : mergeKVs xs ((k',v'):ys)
| k > k' = (k', v') : mergeKVs ((k,v):xs) ys
| otherwise = (k, (merge v v')) : mergeKVs xs ys
{- 7 MARKS -}
{- 1.3.8 Updating keys.
Complete the following definition that updates a 'Config' by
setting a key to a new value (with the effect of adding it if it
doesn't already exist).
Examples:
getKey ["a","b"] (update ["a","b"] "x" emptyConfig) == Just (Value "x")
getKey ["a","b"] (update ["a","c"] "x" emptyConfig) == Nothing
getKey ["a"] (update ["a"] "y" (update ["a"] "x" emptyConfig)) == Just (Value "y")
getKey ["a"] (update [] "x" (update ["a"] "y" emptyConfig)) == Nothing
You should use 'set' and 'merge' to write 'update'. Doing it any
other way will be a lot more work. -}
update :: Key -> String -> Config -> Config
update k s c = merge c (set k s)
{- 1 MARK -}
{----------------------------------------------------------------------}
{- PART 4 : REPRESENTING PROCESSES -}
{----------------------------------------------------------------------}
{- This final part of the exercise is about modelling processes which
input and output bits. Processes are things. They're a kind of
tree, representing a decision process, given by the following
datatype. -}
{- We'll do the setup, then it'll be your turn. -}
data Process
= End -- marks the end of the process, so no more input or output
| Output Bool Process
-- (Output b p) outputs bit b, then continues as p
| Input Process Process
-- (Input pt pf) inputs a bit, continuing as pt if it's
-- True, pf if False
deriving (Show, Eq)
{- Don't expect the data in this type to *do* anything! Rather, they
*represent* processes. We'll see how to interpret them shortly.
Let's have an example process: this process should output False if
its input is True and True if its input is False. -}
notGate :: Process
notGate = Input (Output False End) (Output True End)
{- See? If the input is True, we take the left path and find (Output
False End), otherwise we go right and find (Output True End).
Either way, we make one output and then stop.
How can we make processes go? We need to interpret them. Here's
how. The "process" function takes a Process to interpret, and a
list of input bits in [Bool], then produces the list of output
bits. -}
process :: Process -> [Bool] -> [Bool]
process End bs = []
-- when we're at the end, there is no more output
process (Output b p) bs = b : process p bs
-- the output from (Output b p) had better begin with b, and the rest
-- is whatever comes out from running p on the input
process (Input tp fp) (b : bs) = process (if b then tp else fp) bs
-- when the process wants input, the result depends on the first bit
-- in the input list: if that's True, then we continue with the tp
-- branch; if it's false, we continue with the fp branch. In both
-- cases, we feed the rest of the input bs to the continuing process
process (Input tp fp) [] = []
-- in the unfortunate case where the process wants input but the input
-- list is empty, we're a bit stuck; let's stop and return no output
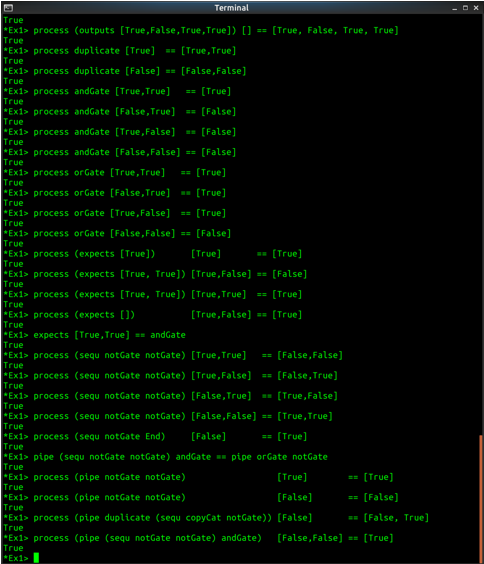
{- Let's try it out. Here are some test examples. Try loading this file
in ghci, then evaluating testNotT and testNotF at the prompt. Do
you get what you expect? -}
testNotT :: [Bool]
testNotT = process notGate [True]
testNotF :: [Bool]
testNotF = process notGate [False]
{- 1.4.0 Outputting a single bit. Write a function that takes a boolean
value and returns a process that outputs that bit and ends. You
should have:
process (output True) [] == [True]
and correspondingly for False. -}
output :: Bool -> Process
output b = Output b End
{- 1 MARK -}
{- 1.4.1 Copycat. Write a definition of a process, similar to the
notGate, that reads its input and outputs it unaltered. You should
have:
process copyCat [True] == [True]
process copyCat [False] == [False]
-}
copyCat :: Process
copyCat = Input (Output True End) (Output False End)
{- 1 MARK -}
{- 1.4.2 Outputting multiple bits. Write a function that takes a list of
bits and generates a process that outputs all of them, in
order. You should have:
process (outputs [True,False,True,True]) [] == [True, False, True, True]
and so on. -}
outputs :: [Bool] -> Process
outputs [] = End
outputs (x:xs) = Output x (outputs xs)
{- 1 MARK -}
{- 1.4.3 Duplication. Write a process that inputs one bit, and then
outputs it *twice*. You should have:
process duplicate [True] == [True,True]
process duplicate [False] == [False,False]
-}
duplicate :: Process
duplicate = Input (Output True (Output True End)) (Output False (Output False End))
{- 1 MARK -}
{- 1.4.4 AND and OR gates.
Write processes that act like an AND gate and an OR gate. You
should have:
process andGate [True,True] == [True]
process andGate [False,True] == [False]
process andGate [True,False] == [False]
process andGate [False,False] == [False]
process orGate [True,True] == [True]
process orGate [False,True] == [True]
process orGate [True,False] == [True]
process orGate [False,False] == [False]
-}
andGate :: Process
andGate = Input (Input (Output True End) (Output False End)) (Input (Output False End) (Output False End))
orGate :: Process
orGate = Input (Input (Output True End) (Output True End)) (Input (Output True End) (Output False End))
{- 1 MARK -}
{- 1.4.5 Expectations.
Write a function that given a list of bits, makes a process that
reads that many bits from the input and outputs 'True' if all the
bits match the input list, and 'False' otherwise. You should have:
process (expects [True]) [True] == [True]
process (expects [True, True]) [True,False] == [False]
process (expects [True, True]) [True,True] == [True]
process (expects []) [True,False] == [True]
If 'expects' is given a list of length 'n', then it should always
read exactly 'n' bits of input! Don't stop reading bits when you
find a mismatch! For example: an andGate always reads two bits, and
you should have:
expects [True,True] == andGate
You will need to write an auxilliary function that continues to
read the input even after bad input has been detected, before
outputting False. -}
expects :: [Bool] -> Process
expects xs = expects' True xs
where
expects' b [] = Output b End
expects' b (x:xs) = if x then
Input (expects' b xs) (expects' False xs)
else
Input (expects' False xs) (expects' b xs)
{- 3 MARKS -}
{- 1.4.6 Sequencing processes.
Complete the following function which combines two processes in
sequence, so that the second begins once the first has ended. That
is, you should 'graft' the second process in place of all the End
markers in the first process. HINT: the structure of this function
is very similar to 'append'. -}
sequ :: Process -> Process -> Process
sequ End p2 = p2
sequ (Output b p1) p2 = Output b (seq p1 p2)
sequ (Input p1t p1f) p2 = Input (sequ p1t p2) (sequ p1f p2)
{- To check that you've got it right, make sure that
sequ notGate End == notGate
process (sequ notGate notGate) [True,True] == [False,False]
process (sequ notGate notGate) [True,False] == [False,True]
process (sequ notGate notGate) [False,True] == [True,False]
process (sequ notGate notGate) [False,False] == [True,True]
process (sequ notGate End) [False] == [True]
That is, sequencing two notGate components gives you a process
which negates two inputs. -}
{- 3 MARKS -}
{- 1.4.7 Piping one process into another.
Write a function which combines two processes so that the output
from the first is used as the input for the second. That is, the
combined process should keep the inputs from the first process and
the outputs from the second process, but hide the communication in
the middle. Give priority to the second process, so the first runs
only when the second is demanding input. We've done some of it for
you, but you may still need to refine the pattern match further.
You should have:
pipe (sequ notGate notGate) andGate == pipe orGate notGate
process (pipe notGate notGate) [True] == [True]
process (pipe notGate notGate) [False] == [False]
process (pipe duplicate (sequ copyCat notGate)) [False] == [False, True]
process (pipe (sequ notGate notGate) andGate) [False,False] == [True]
-}
pipe :: Process -> Process -> Process
pipe p1 End = End
pipe p1 (Output b p2) = Output b (pipe p1 p2)
pipe End (Input t f) = End
-- the second process is hungry, but it starves to death!
pipe (Output b p) (Input t f) = if b then (pipe p t) else (pipe p f)
-- communication: the first process is ready to output, the second
-- wants to input, so the output from the first should determine
-- what happens next, somehow
pipe (Input t1 f1) p2 =
Input (pipe t1 p2) (pipe f1 p2) -- what happens in each case?
-- the second process is hungry, and so is the first, so ask 'the world'
-- for some input
{- 5 MARKS -}
{----------------------------------------------------------------------}
{- END OF EXERCISE -}
{----------------------------------------------------------------------}