Creating an ER Diagram and Normalized Database Schema from CSV Files: A Sample Solution

- QUESTION:
- SOLUTION
- Assumptions
- SCHEMA
Welcome to our comprehensive sample solution for the Database Design assignment, tailored to provide database assignment help. In this project, we illustrate the process of designing a robust relational database by creating an Entity-Relationship (ER) diagram that adheres to best practices in database management. This example demonstrates how to transform poorly structured CSV data into a well-normalized database schema, ensuring data integrity and efficient querying. By following this sample, you'll gain valuable insights into the principles of database design, normalization, and schema implementation, equipping you with the skills to tackle real-world database challenges effectively. For those seeking additional support, we also offer expert help with programming assignments across various subjects.
QUESTION:

SOLUTION
Assumptions
For the design of the database, the data files (.csv) have been analyzed and it has been determined that there is a lot of redundant and repeated information that can be stored in a single table. That said, the creation of a relational database has been proposed where the data is connected by parameters (fields) such as the vaccine id, manufacturer id, country code, etc.
For example, there is a file called us_state_vaccinations.csv which contains information about vaccinations applied in the United States. At the same time, there are the files country_data/Australia.csv and country_data/India.csv which contain the same information but for Australia and India. This information, which is separated into 3 files, can be stored in a single file (or table in the database) specifying the identifier of each country.
The proposed scheme is presented below.
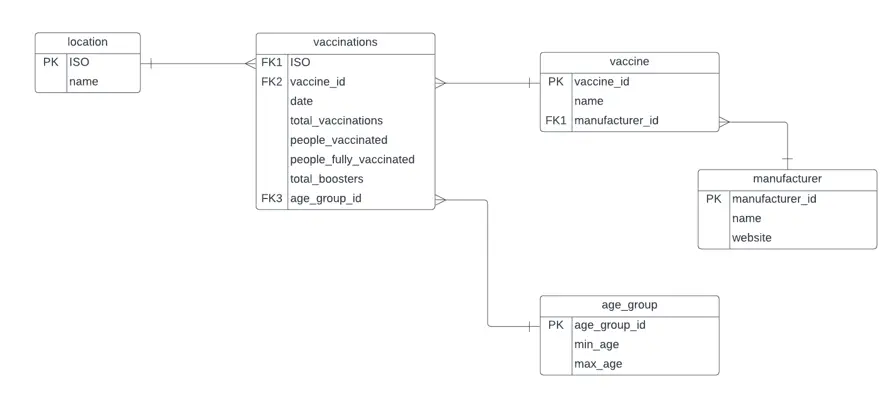
In the schema shown in the previous image, we can see that there are tables related by foreign keys, which has the purpose of reducing redundancy in the data and providing greater organization. This is an example of 3NF (Third normal form) where the rows in each table are organized, and the tables are connected only through the primary keys.
It can be seen that, for a given vaccination report, the ISO determines the name of the location, the vaccine_id determines the name of the vaccine, the manufacturer_id determines the manufacturer of the vaccine (name and website) and the age_group_id determines the age_group of the vaccination.
SCHEMA
CREATE TABLE location (
ISO varchar(3),
name varchar(50),
PRIMARY KEY(ISO)
);
CREATE TABLE manufacturer (
manufacturer_id INT NOT NULL,
name varchar(50),
website varchar(255),
PRIMARY KEY(manufacturer_id)
);
CREATE TABLE vaccine (
vaccine_id INT NOT NULL,
name VARCHAR(255),
manufacturer_id INT,
PRIMARY KEY(vaccine_id),
FOREIGN KEY(manufacturer_id) REFERENCES manufacturer(manufacturer_id)
);
CREATE TABLE age_group (
age_group_id INT NOT NULL,
min_age INT,
max_age INT,
PRIMARY KEY(age_group_id)
);
CREATE TABLE vaccinations (
ISO VARCHAR(3),
vaccine_id INT,
age_group_id INT,
date DATETIME,
total_vaccinations INT,
people_vaccinated INT,
people_fully_vaccinated INT,
total_boosters INT,
FOREIGN KEY(ISO) REFERENCES location(ISO),
FOREIGN KEY(vaccine_id) REFERENCES vaccine(vaccine_id),
FOREIGN KEY(age_group_id) REFERENCES age_group(age_group_id)
);
Similar Samples
We offer expert programming assignment help at affordable prices. Explore our solved assignment samples to see the quality of our work. Based on what you see, you can confidently choose to take advantage of our experts' assistance to solve your own assignments.
C++
C
Database
Embedded System
Python
C++
Data Structures and Algorithms
Python
Database
Database
Database
Database
Database
Database
Database
Database
Database
Database
Database
Database